



前言
其实这个功能于开发来做更简单明了,但是目前开发没有时间来完成这个功能,那就只有运维来完成,起初考虑使用ELK,但是感觉体量太大,我们这个单项目,用不了那么多功能,只是一个日志监控报警,后来发现一个轻量化的mtail这个来监控日志来不错。
一、常见的日志监控解决方案
开源的业务日志监控,我重点推荐以下3个
值得注意的是ELK目前有被EFK取代的趋势
- :ELK-“ELK”是三个开源项目的首字母缩写,这三个项目分别是:Elasticsearch、Logstash 和 Kibana。
Elasticsearch 是一个搜索和分析引擎。
Logstash 是服务器端数据处理管道,能够同时从多个来源采集数据,转换数据,然后将数据发送到诸如 Elasticsearch 等“存储库”中。
Kibana 则可以让用户在 Elasticsearch 中使用图形和图表对数据进行可视化。
-
:Loki,Grafana Labs 团队最新的开源项目,是一个水平可扩展,高可用性,多租户的日志聚合系统。
-
:mtail :它是一个google开发的日志提取工具,从应用程序日志中提取指标以导出到时间序列数据库或时间序列计算器,
用途就是: 实时读取应用程序的日志、 再通过自己编写的脚本进行分析、 最终生成时间序列指标。
工具适合自己的才是最好的,无论是EFK还是Loki都是功能齐全的日志采集系统,当然它们也有各自的优势
二、Mtail介绍
mtail是一种工具,用于从要导出的应用程序日志中提取指标 放入时间序列数据库或时间序列计算器中,用于警报和仪表板。简单来说,就是实时读取应用程序的日志,并且通过自己编写的脚本实时分析,最终生成时间序列指标的工具。Prometheus可以对mtail暴露任何要抓取的指标,也可以配置为将指标发送到collectd、StatsD或Graphite等工具。
官方地址
下载地址
三、安装配置mtail
1、下载安装mtail
wget https://github.com/google/mtail/releases/download/v3.0.0-rc54/mtail_3.0.0-rc54_linux_amd64.tar.gz
mkdir -p /usr/local/mtail-3.0
tar -zxvf mtail_3.0.0-rc54_linux_amd64.tar.gz -C /usr/local/mtail-3.0
2、配置systemd管理启动
vim /usr/lib/systemd/system/mtail.service
[Unit]
Description=mtail server
After=network.target
[Service]
User=prometheus
ExecStart=/usr/local/mtail-3.0/mtail -logtostderr -port 9150 --progs /usr/local/mtail-3.0/test.mtail --logs /usr/local/mtail-3.0/logs/*.log
ExecReload=/bin/kill -HUP $MAINPID
TimeoutStopSec=20s
Restart=on-failure
RestartSec=5
[Install]
WantedBy=multi-user.target
权限配置
由于我使用了prometheus用户,所以系统里面得有这个用户。
useradd -s /sbin/nologin prometheus
chown -R prometheus:prometheus /usr/local/mtail-3.0
mtail 详细参数说明
获取参数说明:
mtail --help
| 参数 | 描述 |
|---|---|
| -address | 绑定HTTP监听器的主机或IP地址 |
| -alsologtostderr | 记录标准错误和文件 |
| -block_profile_rate | 报告goroutine阻塞事件之前的纳秒时间 |
| -collectd_prefix | 发送给collectd的指标的metrics前缀 |
| -collectd_socketpath | collectd unixsock路径,用于向其写入metrics |
| -compile_only | 仅尝试编译mtail脚本程序,不执行,用于测试脚本 |
| -disable_fsnotify | 是否禁用文件动态发现机制。为true时,不会监听动态加载发现的新文件,只会监听程序启动时的文件。 |
| -dump_ast | 解析后dump程序的AST(默认到/tmp/mtail.INFO) |
| -dump_ast_types | 在类型检查之后dump带有类型注释的程序的AST(默认到/tmp/mtail.INFO) |
| -dump_bytecode | dump程序字节码 |
| -emit_metric_timestamp | 发出metric的记录时间戳。如果禁用(默认设置),则不会向收集器发送显式时间戳。 |
| -emit_prog_label | 在导出的变量里面展示’prog’对应的标签。默认为true |
| -expired_metrics_gc_interval | metric的垃圾收集器运行间隔(默认为1h0m0s) |
| -graphite_host_port | graphite carbon服务器地址,格式Host:port。用于向graphite carbon服务器写入metrics |
| -graphite_prefix | 发送给graphite指标的metrics前缀 |
| -ignore_filename_regex_pattern | 需要忽略的日志文件名字,支持正则表达式。使用场景:当-logs参数指定的为一个目录时,可以使用ignore_filename_regex_pattern 参数来忽略一部分文件 |
| -jaeger_endpoint | 如果设为true,可以将跟踪导出到Jaeger跟踪收集器。使用–jaeger_endpoint标志指定Jaeger端点URL |
| -log_backtrace_at | 当日志记录命中设置的行N时,发出堆栈跟踪 |
| -log_dir | mtail程序的日志文件的目录,与logtostderr作用类似,如果同时配置了logtostderr参数,则log_dir参数无效 |
| -logs | 监控的日志文件列表,可以使用,分隔多个文件,也可以多次使用-logs参数,也可以指定一个文件目录,支持通配符*,指定文件目录时需要对目录使用单引号。如-logs a.log,b.log,c.log-logs a.log -logs-b.log -logs c.log-logs ‘/export/logs/*.log’ |
| -logtostderr | 直接输出标准错误信息,编译问题也直接输出 |
| -metric_push_interval_seconds | metric推送时间间隔,单位:秒,默认60秒 |
| -metric_push_write_deadline | 在出现错误退出之前等待推送成功的时间。(默认10s) |
| -mtailDebug | 设置解析器debug级别 |
| -mutex_profile_fraction | 报告的互斥锁争用事件的分数。0关闭。(此参数为直译,不太理解啥意思) |
| -one_shot | 此参数将编译并运行mtail程序,然后从指定的文件开头开始读取日志(从头开始读取日志,不是实时tail),然后将收集的所有metrics打印到日志中。此参数用于验证mtail程序是否有预期输出,不用于生产环境。 |
| -override_timezone | 设置时区,如果使用此参数,将在时间戳转换中使用指定的时区来替代UTC |
| -poll_interval | 设置轮询所有日志文件以获取数据的间隔;必须为正,如果为零将禁用轮询。使用轮询模式,将仅轮询在mtail启动时找到的文件 |
| -port | 监听的http端口,默认3903 |
| -progs | mtail脚本程序所在路径 |
| -stale_log_gc_interval | stale的垃圾收集器运行间隔(默认为1h0m0s) |
| -statsd_hostport | statsd地址,格式Host:port。用于向statsd写入metrics |
| -statsd_prefix | 发送给statsd指标的metrics前缀 |
| -stderrthreshold | 严重性级别达到阈值以上的日志信息除了写入日志文件以外,还要输出到stderr。各严重性级别对应的数值:INFO—0,WARNING—1,ERROR—2,FATAL—3,默认值为2. |
| -syslog_use_current_year | 如果时间戳没有年份,则用当前年替代。(默认为true) |
| -trace_sample_period | 用于设置跟踪的采样频率和发送到收集器的频率。将其设置为100,则100条收集一条追踪。 |
| -v | v日志的日志级别,该设置可能被 vmodule标志给覆盖.默认为0. |
| -version | 打印mtail版本 |
| -vmodule | 按文件或模块来设置日志级别,如:-vmodule=mapreduce=2,file=1,gfs*=3 |
虽然参数比较多,其实用到的不多,上面systemd里面已经使用的参数就是常用的。
新建规则
vim /usr/local/mtail-3.0/test.mtail
gauge error_log by file,info
/\[(?P<date>\d{2}:\d{2}:\d{2}:\d{3})\]\ \[ERROR\]\s(?P<info>.*)/ {
error_log[getfilename()][$info] = timestamp()
}
- 这个规则一定得要自己去写,主要是匹配时间。我这个配置是返回一个时间值,我学习了https://www.cnblogs.com/lifuqiang/articles/16880624.html大神的思路,非常nice。这样配合prometheus来告警,他收到error就告警,最新的error日志。而不是error到多少条才告警。然后prometheus配置规则,超过2分钟就不管了。有新的告警才会继续告警。这是我们项目所需要的。
- 我列几个官方给的常用的时间匹配规则:
- 首先官方的文档:点击这里
- 我读了很久,智商不够只看懂了一些,常用时间匹配。
# The `syslog' decorator defines a procedure. When a block of mtail code is # "decorated", it is called before entering the block. The block is entered # when the keyword `next' is reached. def syslog { /(?P<date>(?P<legacy_date>\w+\s+\d+\s+\d+:\d+:\d+)|(?P<rfc3339_date>\d{4}-\d{2}-\d{2}T\d{2}:\d{2}:\d{2}.\d+[+-]\d{2}:\d{2}))/ + /\s+(?:\w+@)?(?P<hostname>[\w\.-]+)\s+(?P<application>[\w\.-]+)(?:\[(?P<pid>\d+)\])?:\s+(?P<message>.*)/ { # If the legacy_date regexp matched, try this format. len($legacy_date) > 0 { strptime($legacy_date, "Jan _2 15:04:05") } # If the RFC3339 style matched, parse it this way. len($rfc3339_date) > 0 { strptime($rfc3339_date, "2006-01-02T15:04:05-07:00") } # Call into the decorated block next } } - 上面他把规则写成一个方法,可以在后面直接调用,这个要去匹配你们项目报出error时候的格式。
比如:我们项目目前error的格式:
[11:27:32:878] [ERROR] - org.springframework.boot.SpringApplication.reportFailurr
e(SpringApplication.java:837) - Application run failed
- 上面的 /[(?P
\d{2}:\d{2}:\d{2}:\d{3})] 就是去匹配这个格式。接下来\ 后面有个空格,就是时间后面的空格。[ERROR]就是关键字。
这个匹配成功就ok了。不然prometheus拿不到error_log字段,就无法告警。(我其实想把后面一行也打到info里面,但是不太了解这个语法,有懂的兄弟说一下。)
启动mtail
systemctl enable mtail.service --now && systemctl status mtail.service
● mtail.service - mtail server
Loaded: loaded (/lib/systemd/system/mtail.service; enabled; vendor preset:>
Active: active (running) since Fri 2024-03-08 03:25:56 UTC; 5h 44min ago
Main PID: 1071304 (mtail)
Tasks: 10 (limit: 9347)
Memory: 17.5M
CPU: 24.385s
CGroup: /system.slice/mtail.service
└─1071304 /usr/local/mtail-3.0/mtail -logtostderr --progs /usr/loc>
Mar 08 03:25:56 ubuntu mtail[1071304]: I0308 03:25:56.460933 1071304 logstream.>
Mar 08 03:25:56 ubuntu mtail[1071304]: I0308 03:25:56.460998 1071304 tail.go:29>
Mar 08 03:25:56 ubuntu mtail[1071304]: I0308 03:25:56.461013 1071304 logstream.>
Mar 08 03:25:56 ubuntu mtail[1071304]: I0308 03:25:56.461044 1071304 tail.go:29>
Mar 08 03:25:56 ubuntu mtail[1071304]: I0308 03:25:56.461074 1071304 mtail.go:1>
Mar 08 04:25:56 ubuntu mtail[1071304]: I0308 04:25:56.460560 1071304 store.go:1>
Mar 08 05:25:56 ubuntu mtail[1071304]: I0308 05:25:56.459991 1071304 store.go:1>
Mar 08 06:25:57 ubuntu mtail[1071304]: I0308 06:25:56.846822 1071304 store.go:1>
Mar 08 07:25:56 ubuntu mtail[1071304]: I0308 07:25:56.461377 1071304 store.go:1>
Mar 08 08:25:56 ubuntu mtail[1071304]: I0308 08:25:56.460894 1071304 store.go:1>
配置prometheus
1、配置监控项
vim /usr/local/prometheus/prometheus.yml
### 添加告警规则
rule_files:
- "./rules/error_logs.yml"
### 添加job
- job_name: "error_logs"
static_configs:
- targets: ["172.16.2.38:9150"]
2、配置告警项
vim /usr/local/prometheus/rules/error_logs.yml
groups:
- name: 错误日志告警
rules:
- alert: 服务错误日志抛出
expr: time() - error_log <= 120
for: 1s # 告警持续时间,超过这个时间才会发送给alertmanager
labels:
severity: 严重告警
annotations:
title: "[{{$labels.instance }}错误日志告警]"
info: "错误文件{{ $labels.file }},错误内容是:{{ $labels.info }},详细信息请登录服务器查看!"
3、配置完成。
由于之前我已经配置过告警服务那些了,所以直接验证。如果不会的小伙伴去这里:alertmanager 配置与使用
我直接改了项目的redis配置,连接不上就报错,结果:
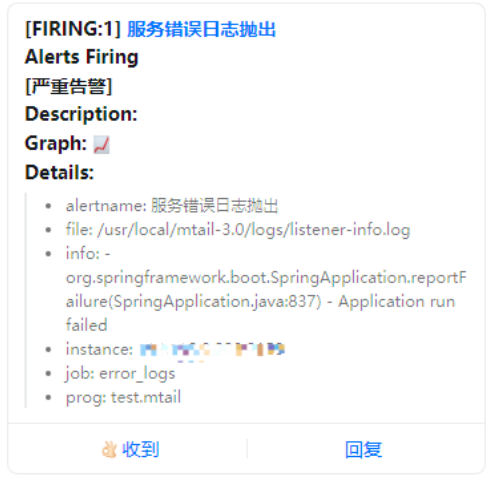
2分钟后告警恢复。
评论区