



背景
Kubernetes 1.24新特性
从kubelet中移除dockershim
自1.20版本被弃用之后,dockershim组件终于在1.24的kubelet中被删除。从1.24开始,大家需要使用其他受到支持的运行时选项(例如containerd或CRI-O);如果您选择Docker Engine作为运行时,则需要使用cri-dockerd。
对于kubelet和containerd重要提示
在升级至1.24之前,请确认containerd版本
- #以下容器运行时已经或即将全面兼容Kubernetes 1.24:
containerd v1.6.4及更高,v1.5.11及更高
CRI-O 1.24及更高
若CNI插件尚未升级且/或CNI配置文件中未声明CNI配置版本时,则containerd v1.6.0-v1.6.3版本将导致Pod CNI网络setup及tear down发生问题。containerd团队报告称,这些问题已经在containerd v1.6.4中得到解决。
在containerd v1.6.0-v1.6.3时,如果你未升级CNI插件且/或声明CNI配置版本,则可能遇到CNI版本不兼容或无法为沙箱删除网络等错误
Kubernetes 1.24新特性
-
各beta API默认关闭
在默认情况下,新的各beta API不会在集群内得到启用。但全部原有beta API及其新版本将在1.24中继续默认启用 -
OpenAPI v3
Kubernetes 1.24开始为API的OpenAPI v3发布格式提供beta支持。 -
存储容量与存储卷扩展双双迎来通用版本
存储容量跟踪通过CSIStorageCapacity对象公开当前可用的存储容量,并对使用后续绑定的CSI存储卷的pod进行调度增强。
存储卷扩展则新增对现有持久卷的重新调整功能。 -
NonPreemptingPriority迎来稳定版
此功能为PriorityClasses添加了新的选项,可开启或关闭Pod抢占机制 -
存储插件迁移
目前Kubernetes开发团队正在迁移树内存储插件,希望在实现CSI插件的同时、保持原有API的正常起效。Azure Disk与OpenStack Cinder等插件已经完成了迁移。 -
gRPC探针升级至beta版
在1.24版本中,gRPC探针功能已经进入beta阶段且默认启用。现在,大家可以在Kubernetes中为自己的gRPC应用程序原生配置启动、活动与就绪探测,而且无需公开HTTP商战或者使用额外的可执行文件。 -
Kubelet证书提供程序升级至beta版
最初在Kubernetes 1.20版本中以alpha版亮相的kubelet镜像证书提供程序现已升级至beta版。现在,kubelet将使用exec插件动态检索容器镜像注册表的凭证,而不再将凭证存储在节点文件系统之上。 -
避免为服务分配IP时发生冲突
Kubernetes 1.24引入了一项新的选择性功能,允许用户为服务的静态IP分配地址保留一个软范围。通过手动启用此项功能,集群将从您指定的服务IP池中自动获取地址,从而降低冲突风险。
也就是说,服务的ClusterIP能够以下列方式分配:
动态分配,即集群将在配置的服务IP范围内自动选择一个空闲IP。
静态分配,意味着用户需要在已配置的服务IP范围内指定一个IP。
服务ClusterIP是唯一的;因此若尝试使用已被分配的ClusterIP进行服务创建,则会返回错误结果。
环境准备
本地有kubernetes 1.18环境,(没有就跳过) 接下来对环境进行初始化
#目前kubernetes版本
[root@k8s-01 ~]# kubectl get node
NAME STATUS ROLES AGE VERSION
k8s-01 Ready master 243d v1.18.3
k8s-02 Ready master 243d v1.18.3
k8s-03 Ready master 243d v1.18.3
k8s-04 Ready <none> 243d v1.18.3
k8s-05 Ready <none> 243d v1.18.3
卸载集群命令
#建议所有服务器都执行
#!/bin/bash
kubeadm reset -f
modprobe -r ipip
lsmod
rm -rf ~/.kube/
rm -rf /etc/kubernetes/
rm -rf /etc/systemd/system/kubelet.service.d
rm -rf /etc/systemd/system/kubelet.service
rm -rf /usr/bin/kube*
rm -rf /etc/cni
rm -rf /opt/cni
rm -rf /var/lib/etcd
rm -rf /var/etcd
yum -y remove kubeadm* kubectl* kubelet* docker*
reboot
基础环境配置
| IP地址 | 主机名 | 服务 | 配置 |
|---|---|---|---|
| 192.168.31.10 | k8s-01 | k8s-master、containerd、keepalived、nginx 2c8g | |
| 192.168.31.11 | k8s-02 | k8s-master、containerd、keepalived、nginx 2c8g | |
| 192.168.31.12 | k8s-03 | k8s-master、containerd、keepalived、nginx 2c8g | |
| 192.168.31.13 | k8s-04 | k8s-node、containerd 1c4g | |
| 192.168.31.14 | k8s-05 | k8s-node、containerd 1c4g |
VIP: 192.168.31.111 域名:apiserver.frps.cn
- apiserver.frps.cn:6443 为VIP
- kube-apiserver 三台节点
- kube-schedulet 三台节点
- kube-controller-manager 三台节点
- ETCD 三台节点
服务版本
| 服务名称 | 版本号 |
|---|---|
| 内核 | 5.14.3-1.el7.elrepo.x86_64 |
| containerd | v1.6.4 |
| ctr | v1.6.4 |
| k8s | 1.24 |
初始化环境
初始化环境需要全部节点都执行
hostnamectl set-hostname k8s01 #所有机器按照要求修改
bash #刷新主机名
#配置host
cat >> /etc/hosts <<EOF
192.168.31.100 k8s-01
192.168.31.101 k8s-02
192.168.31.102 k8s-03
192.168.31.103 k8s-04
192.168.31.104 k8s-05
EOF
#设置k8s-01为分发机 (只需要在k8s-01服务器操作即可)
wget -O /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-7.repo
curl -o /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo
yum install -y expect
#分发公钥
ssh-keygen -t rsa -P "" -f /root/.ssh/id_rsa
for i in k8s-01 k8s-02 k8s-03 k8s-04 k8s-05;do
expect -c "
spawn ssh-copy-id -i /root/.ssh/id_rsa.pub root@$i
expect {
"*yes/no*" {send "yesr"; exp_continue}
"*password*" {send "123456r"; exp_continue}
"*Password*" {send "123456r";}
} "
done
我这里密码为123456,请根据需求自行更改
所有节点关闭Selinux、iptables、swap分区
systemctl stop firewalld
systemctl disable firewalld
iptables -F && iptables -X && iptables -F -t nat && iptables -X -t nat
iptables -P FORWARD ACCEPT
swapoff -a
sed -i '/ swap / s/^(.*)$/#1/g' /etc/fstab
setenforce 0
sed -i 's/^SELINUX=.*/SELINUX=disabled/' /etc/selinux/config
所有节点配置yum源
curl -o /etc/yum.repos.d/CentOS-Base.repo https://mirrors.aliyun.com/repo/Centos-7.repo
wget -O /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-7.repo
yum clean all
yum makecache
新安装的服务器可以安装下面的软件包,可以解决99%的依赖问题
yum -y install gcc gcc-c++ make autoconf libtool-ltdl-devel gd-devel freetype-devel libxml2-devel libjpeg-devel libpng-devel openssh-clients openssl-devel curl-devel bison patch libmcrypt-devel libmhash-devel ncurses-devel binutils compat-libstdc++-33 elfutils-libelf elfutils-libelf-devel glibc glibc-common glibc-devel libgcj libtiff pam-devel libicu libicu-devel gettext-devel libaio-devel libaio libgcc libstdc++ libstdc++-devel unixODBC unixODBC-devel numactl-devel glibc-headers sudo bzip2 mlocate flex lrzsz sysstat lsof setuptool system-config-network-tui system-config-firewall-tui ntsysv ntp pv lz4 dos2unix unix2dos rsync dstat iotop innotop mytop telnet iftop expect cmake nc gnuplot screen xorg-x11-utils xorg-x11-xinit rdate bc expat-devel compat-expat1 tcpdump sysstat man nmap curl lrzsz elinks finger bind-utils traceroute mtr ntpdate zip unzip vim wget net-tools
由于开启内核 ipv4 转发需要加载 br_netfilter 模块,所以加载下该模块:
modprobe br_netfilter
modprobe ip_conntrack
#每台节点
将上面的命令设置成开机启动,因为重启后模块失效,下面是开机自动加载模块的方式。首先新建 /etc/rc.sysinit 文件,内容如下所示:
cat >>/etc/rc.sysinit<<EOF
#!/bin/bash
for file in /etc/sysconfig/modules/*.modules ; do
[ -x $file ] && $file
done
EOF
然后在/etc/sysconfig/modules/目录下新建如下文件:
echo "modprobe br_netfilter" >/etc/sysconfig/modules/br_netfilter.modules
echo "modprobe ip_conntrack" >/etc/sysconfig/modules/ip_conntrack.modules
增加权限
chmod 755 /etc/sysconfig/modules/br_netfilter.modules
chmod 755 /etc/sysconfig/modules/ip_conntrack.modules
然后重启后,模块就可以自动加载了
优化内核参数
cat > kubernetes.conf <<EOF
net.bridge.bridge-nf-call-iptables=1
net.bridge.bridge-nf-call-ip6tables=1
net.ipv4.ip_forward=1
vm.swappiness=0 # 禁止使用 swap 空间,只有当系统 OOM 时才允许使用它
vm.overcommit_memory=1 # 不检查物理内存是否够用
vm.panic_on_oom=0 # 开启 OOM
fs.inotify.max_user_instances=8192
fs.inotify.max_user_watches=1048576
fs.file-max=52706963
fs.nr_open=52706963
net.ipv6.conf.all.disable_ipv6=1
net.netfilter.nf_conntrack_max=2310720
EOF
cp kubernetes.conf /etc/sysctl.d/kubernetes.conf
sysctl -p /etc/sysctl.d/kubernetes.conf
#分发到所有节点
for i in k8s-02 k8s-03 k8s-04 k8s-05
do
scp kubernetes.conf root@$i:/etc/sysctl.d/
ssh root@$i sysctl -p /etc/sysctl.d/kubernetes.conf
ssh root@$i echo '1' >> /proc/sys/net/ipv4/ip_forward
done
#for后面节点根据需求修改
bridge-nf 使得netfilter可以对Linux网桥上的 IPv4/ARP/IPv6 包过滤。比如,设置net.bridge.bridge-nf-call-iptables=1后,二层的网桥在转发包时也会被 iptables的 FORWARD 规则所过滤。常用的选项包括:
net.bridge.bridge-nf-call-arptables:是否在 arptables 的 FORWARD 中过滤网桥的 ARP 包
net.bridge.bridge-nf-call-ip6tables:是否在 ip6tables 链中过滤 IPv6 包
net.bridge.bridge-nf-call-iptables:是否在 iptables 链中过滤 IPv4 包
net.bridge.bridge-nf-filter-vlan-tagged:是否在 iptables/arptables 中过滤打了 vlan 标签的包。
所有节点安装ipvs
为什么要使用IPVS,从k8s的1.8版本开始,kube-proxy引入了IPVS模式,IPVS模式与iptables同样基于Netfilter,但是采用的hash表,因此当service数量达到一定规模时,hash查表的速度优势就会显现出来,从而提高service的服务性能。
ipvs依赖于nf_conntrack_ipv4内核模块,4.19包括之后内核里改名为nf_conntrack,1.13.1之前的kube-proxy的代码里没有加判断一直用的nf_conntrack_ipv4,好像是1.13.1后的kube-proxy代码里增加了判断,我测试了是会去load nf_conntrack使用ipvs正常
cat > /etc/sysconfig/modules/ipvs.modules <<EOF
#!/bin/bash
modprobe -- ip_vs
modprobe -- ip_vs_rr
modprobe -- ip_vs_wrr
modprobe -- ip_vs_sh
modprobe -- nf_conntrack
EOF
chmod 755 /etc/sysconfig/modules/ipvs.modules && bash /etc/sysconfig/modules/ipvs.modules && lsmod | grep -e ip_vs -e nf_conntrack
#查看是否已经正确加载所需的内核模块
所有节点安装ipset
yum install ipset -y
ipset介绍
iptables是Linux服务器上进行网络隔离的核心技术,内核在处理网络请求时会对iptables中的策略进行逐条解析,因此当策略较多时效率较低;而是用IPSet技术可以将策略中的五元组(协议,源地址,源端口,目的地址,目的端口)合并到有限的集合中,可以大大减少iptables策略条目从而提高效率。测试结果显示IPSet方式效率将比iptables提高100倍
- 为了方面ipvs管理,这里安装一下ipvsadm。
yum install ipvsadm -y
所有节点设置系统时区
timedatectl set-timezone Asia/Shanghai
#将当前的 UTC 时间写入硬件时钟
timedatectl set-local-rtc 0
#重启依赖于系统时间的服务
systemctl restart rsyslog
systemctl restart crond
升级内核 (可选方案)
rpm --import https://www.elrepo.org/RPM-GPG-KEY-elrepo.org
rpm -Uvh http://www.elrepo.org/elrepo-release-7.0-3.el7.elrepo.noarch.rpm
#默认安装为最新内核
yum --enablerepo=elrepo-kernel install kernel-ml
#修改内核顺序
grub2-set-default 0 && grub2-mkconfig -o /etc/grub2.cfg
#使用下面命令看看确认下是否启动默认内核指向上面安装的内核
grubby --default-kernel
#这里的输出结果应该为我们升级后的内核信息
reboot
#可以等所有初始化步骤结束进行reboot操作
接下来更新一下软件包版本
yum update -y
Containerd 安装
在安装containerd前,我们需要优先升级libseccomp
在centos7中yum下载libseccomp的版本是2.3的,版本不满足我们最新containerd的需求,需要下载2.4以上的
Containerd需要在所有节点升级安装
#卸载原来的
[i4t@web01 ~]# rpm -qa | grep libseccomp
libseccomp-devel-2.3.1-4.el7.x86_64
libseccomp-2.3.1-4.el7.x86_64
[i4t@web01 ~]# rpm -e libseccomp-devel-2.3.1-4.el7.x86_64 --nodeps
[i4t@web01 ~]# rpm -e libseccomp-2.3.1-4.el7.x86_64 --nodeps
#下载高于2.4以上的包
[i4t@web01 ~]# wget http://rpmfind.net/linux/centos/8-stream/BaseOS/x86_64/os/Packages/libseccomp-2.5.1-1.el8.x86_64.rpm
#安装
[i4t@web01 ~]# rpm -ivh libseccomp-2.5.1-1.el8.x86_64.rpm
warning: libseccomp-2.5.1-1.el8.x86_64.rpm: Header V3 RSA/SHA256 Signature, key ID 8483c65d: NOKEY
Preparing... ################################# [100%]
Updating / installing...
1:libseccomp-2.5.1-1.el8 ################################# [100%]
#查看当前版本
[root@web01 ~]# rpm -qa | grep libseccomp
libseccomp-2.5.1-1.el8.x86_64
下载安装containerd
github地址:https://containerd.io/downloads/
Containerd安装我们使用1.6.4版本号
containerd-1.6.4-linux-amd64.tar.gz 只包含containerd
cri-containerd-cni-1.6.4-linux-amd64.tar.gz 包含containerd以及cri runc等相关工具包,建议下载本包
#下载tar.gz包
#containerd工具包,包含cri runc等
wget https://github.com/containerd/containerd/releases/download/v1.6.4/cri-containerd-cni-1.6.4-linux-amd64.tar.gz
#备用下载地址
wget https://d.frps.cn/file/kubernetes/containerd/cri-containerd-cni-1.6.4-linux-amd64.tar.gz
- 工具包文件如下
#cri-containerd-cni会将我们整个containerd相关的依赖都进行下载下来
[root@k8s-01 containerd]# tar zxvf cri-containerd-cni-1.6.4-linux-amd64.tar.gz -C / #我们直接让它给我们对应的目录给替换掉
etc/
etc/systemd/
etc/systemd/system/
etc/systemd/system/containerd.service
etc/crictl.yaml
etc/cni/
etc/cni/net.d/
etc/cni/net.d/10-containerd-net.conflist
usr/
usr/local/
usr/local/sbin/
usr/local/sbin/runc
usr/local/bin/
usr/local/bin/crictl
usr/local/bin/ctd-decoder
usr/local/bin/ctr
usr/local/bin/containerd-shim
usr/local/bin/containerd
usr/local/bin/containerd-shim-runc-v1
usr/local/bin/critest
usr/local/bin/containerd-shim-runc-v2
usr/local/bin/containerd-stress
opt/
opt/containerd/
opt/containerd/cluster/
opt/containerd/cluster/version
opt/containerd/cluster/gce/
opt/containerd/cluster/gce/cni.template
opt/containerd/cluster/gce/env
opt/containerd/cluster/gce/configure.sh
opt/containerd/cluster/gce/cloud-init/
opt/containerd/cluster/gce/cloud-init/node.yaml
opt/containerd/cluster/gce/cloud-init/master.yaml
opt/cni/
opt/cni/bin/
opt/cni/bin/firewall
opt/cni/bin/portmap
opt/cni/bin/host-local
opt/cni/bin/ipvlan
opt/cni/bin/host-device
opt/cni/bin/sbr
opt/cni/bin/vrf
opt/cni/bin/static
opt/cni/bin/tuning
opt/cni/bin/bridge
opt/cni/bin/macvlan
opt/cni/bin/bandwidth
opt/cni/bin/vlan
opt/cni/bin/dhcp
opt/cni/bin/loopback
opt/cni/bin/ptp
上面的文件都是二进制文件,直接移动到对应的目录并配置好环境变量就可以进行使用了。
如果我们机器上通过yum安装docker了,可以用下面的命令进行卸载
sudo yum remove docker
docker-client
docker-client-latest
docker-common
docker-latest
docker-latest-logrotate
docker-logrotate
docker-engine
接下来我们为每台服务器配置Containerd
#创建配置文件目录
[root@k8s-01 ~]# mkdir /etc/containerd -p
#生成默认配置文件
[root@k8s-01 ~]# containerd config default > /etc/containerd/config.toml
#--config,-c可以在启动守护程序时更改此路径
#配置文件的默认路径位于/etc/containerd/config.toml
替换默认pause镜像地址
- 默认情况下k8s.gcr.io无法访问,所以使用我提供的阿里云镜像仓库地址即可
# 更改sandbox_image
sed -ri 's#k8s.gcr.io\/pause:3.6#registry.aliyuncs.com\/google_containers\/pause:3.7#' /etc/containerd/config.toml
# endpoint位置添加阿里云的镜像源
sed -ri 's#https:\/\/registry-1.docker.io#https:\/\/registry.aliyuncs.com#' /etc/containerd/config.toml
配置systemd作为容器的cgroup driver
sed -i 's/SystemdCgroup = false/SystemdCgroup = true/' /etc/containerd/config.toml
Containerd官方操作手册
默认cri-containerd-cni包中会有containerd启动脚本,我们已经解压到对应的目录,可以直接调用启动
[root@k8s-01 ~]# systemctl enable containerd --now && systemctl status containerd
Created symlink from /etc/systemd/system/multi-user.target.wants/containerd.service to /etc/systemd/system/containerd.service.
● containerd.service - containerd container runtime
Loaded: loaded (/etc/systemd/system/containerd.service; enabled; vendor preset: disabled)
Active: active (running) since Thu 2022-05-12 22:59:19 EDT; 3s ago
Docs: https://containerd.io
Process: 30048 ExecStartPre=/sbin/modprobe overlay (code=exited, status=0/SUCCESS)
Main PID: 30050 (containerd)
Memory: 24.5M
CGroup: /system.slice/containerd.service
└─30050 /usr/local/bin/containerd
May 12 22:59:19 web01 containerd[30050]: time="2022-05-12T22:59:19.153514446-04:00" level=info msg="Get image filesystem path "/var/lib/containerd/io.containerd.snapshotter.v1.overlayfs""
May 12 22:59:19 web01 containerd[30050]: time="2022-05-12T22:59:19.154085898-04:00" level=info msg="Start subscribing containerd event"
May 12 22:59:19 web01 containerd[30050]: time="2022-05-12T22:59:19.154137039-04:00" level=info msg="Start recovering state"
May 12 22:59:19 web01 containerd[30050]: time="2022-05-12T22:59:19.154230615-04:00" level=info msg="Start event monitor"
May 12 22:59:19 web01 containerd[30050]: time="2022-05-12T22:59:19.154276701-04:00" level=info msg="Start snapshots syncer"
May 12 22:59:19 web01 containerd[30050]: time="2022-05-12T22:59:19.154299287-04:00" level=info msg="Start cni network conf syncer for default"
May 12 22:59:19 web01 containerd[30050]: time="2022-05-12T22:59:19.154316094-04:00" level=info msg="Start streaming server"
May 12 22:59:19 web01 containerd[30050]: time="2022-05-12T22:59:19.154675632-04:00" level=info msg=serving... address=/run/containerd/containerd.sock.ttrpc
May 12 22:59:19 web01 containerd[30050]: time="2022-05-12T22:59:19.154755704-04:00" level=info msg=serving... address=/run/containerd/containerd.sock
May 12 22:59:19 web01 containerd[30050]: time="2022-05-12T22:59:19.155220379-04:00" level=info msg="containerd successfully booted in 0.027654s"
ctr在我们解压包中已经附带了,直接可以使用
[root@k8s-01 ~]# ctr version
Client: #ctr版本号
Version: v1.6.4
Revision: 212e8b6fa2f44b9c21b2798135fc6fb7c53efc16
Go version: go1.17.9
Server:
Version: v1.6.4 #containerd版本号
Revision: 212e8b6fa2f44b9c21b2798135fc6fb7c53efc16
UUID: b376d7b6-c97e-4b39-8144-9624ade3ba84
#可以使用下面命令查看containerd版本号
[root@k8s-01 ~]# containerd --version
containerd github.com/containerd/containerd v1.6.4 212e8b6fa2f44b9c21b2798135fc6fb7c53efc16
设置crictl
cat << EOF >> /etc/crictl.yaml
runtime-endpoint: unix:///var/run/containerd/containerd.sock
image-endpoint: unix:///var/run/containerd/containerd.sock
timeout: 10
debug: false
EOF
api-server 高可用部署 (单master可跳过)
nginx代理后端3台apiserver,所以需要在每台apiserver中安装nginx。keeplived起到vip的作用
需要在master节点安装
#首先我们在原有的基础上添加一个host,只需要在master节点上执行即可
cat >>/etc/hosts<< EOF
192.168.31.10 k8s-master-01
192.168.31.11 k8s-master-02
192.168.31.12 k8s-master-03
192.168.31.111 apiserver.frps.cn
EOF
安装nginx
为了方便后面扩展插件,我这里使用编译安装nginx
#编译安装nginx
#安装依赖
yum install pcre pcre-devel openssl openssl-devel gcc gcc-c++ automake autoconf libtool make wget vim lrzsz -y
wget https://nginx.org/download/nginx-1.20.2.tar.gz
tar xf nginx-1.20.2.tar.gz
cd nginx-1.20.2/
useradd nginx -s /sbin/nologin -M
./configure --prefix=/opt/nginx/ --with-pcre --with-http_ssl_module --with-http_stub_status_module --with-stream --with-http_stub_status_module --with-http_gzip_static_module
make && make install
#使用systemctl管理,并设置开机启动
cat >/usr/lib/systemd/system/nginx.service<<EOF
# /usr/lib/systemd/system/nginx.service
[Unit]
Description=The nginx HTTP and reverse proxy server
After=network.target sshd-keygen.service
[Service]
Type=forking
EnvironmentFile=/etc/sysconfig/sshd
ExecStartPre=/opt/nginx/sbin/nginx -t -c /opt/nginx/conf/nginx.conf
ExecStart=/opt/nginx/sbin/nginx -c /opt/nginx/conf/nginx.conf
ExecReload=/opt/nginx/sbin/nginx -s reload
ExecStop=/opt/nginx/sbin/nginx -s stop
Restart=on-failure
RestartSec=42s
[Install]
WantedBy=multi-user.target
EOF
#开机启动
[root@k8s-01 nginx-1.20.2]# systemctl enable nginx --now
Created symlink from /etc/systemd/system/multi-user.target.wants/nginx.service to /usr/lib/systemd/system/nginx.service.
# yum安装nginx
yum install nginx -y
#yum安装nginx需要注意下面的配置文件路径就是/etc/nginx/conf/nginx.conf
检查服务是否启动
[root@k8s-01 nginx-1.20.2]# ps -ef|grep nginx
root 84040 1 0 20:15 ? 00:00:00 nginx: master process /opt/nginx/sbin/nginx -c /opt/nginx/conf/nginx.conf
nobody 84041 84040 0 20:15 ? 00:00:00 nginx: worker process
root 84044 51752 0 20:16 pts/0 00:00:00 grep --color=auto nginx
修改nginx配置文件
vim nginx.conf
user nginx nginx;
worker_processes auto;
events {
worker_connections 20240;
use epoll;
}
error_log /var/log/nginx_error.log info;
stream {
upstream kube-servers {
hash $remote_addr consistent;
server k8s-master-01:6443 weight=5 max_fails=1 fail_timeout=3s; #这里可以写IP
server k8s-master-02:6443 weight=5 max_fails=1 fail_timeout=3s;
server k8s-master-03:6443 weight=5 max_fails=1 fail_timeout=3s;
}
server {
listen 8443 reuseport;
proxy_connect_timeout 3s;
# 加大timeout
proxy_timeout 3000s;
proxy_pass kube-servers;
}
}
#分发到其它master节点
for i in k8s-02 k8s-03
do
scp nginx.conf root@$i:/opt/nginx/conf/
ssh root@$i systemctl restart nginx
done
配置Keeplived
前面我们也说了,高可用方案需要一个VIP,供集群内部访问
yum install -y keepalived
#在所有master节点安装
修改配置文件
- router_id 节点IP
- mcast_src_ip 节点IP
- virtual_ipaddress VIP
请根据自己IP实际上情况修改
cat > /etc/keepalived/keepalived.conf <<EOF
! Configuration File for keepalived
global_defs {
router_id 192.168.31.10 #节点ip,master每个节点配置自己的IP
}
vrrp_script chk_nginx {
script "/etc/keepalived/check_port.sh 8443"
interval 2
weight -20
}
vrrp_instance VI_1 {
state MASTER
interface eth0
virtual_router_id 251
priority 100
advert_int 1
mcast_src_ip 192.168.31.10 #节点IP
nopreempt
authentication {
auth_type PASS
auth_pass 11111111
}
track_script {
chk_nginx
}
virtual_ipaddress {
192.168.31.111 #VIP
}
}
EOF
#编写健康检查脚本
vim /etc/keepalived/check_port.sh
CHK_PORT=$1
if [ -n "$CHK_PORT" ];then
PORT_PROCESS=`ss -lt|grep $CHK_PORT|wc -l`
if [ $PORT_PROCESS -eq 0 ];then
echo "Port $CHK_PORT Is Not Used,End."
exit 1
fi
else
echo "Check Port Cant Be Empty!"
fi
启动keepalived
systemctl enable --now keepalived
测试vip是否正常
ping vip
ping apiserver.frps.cn #我们的域名
Kubeadm 安装配置
首先我们需要在k8s-01配置kubeadm源
下面kubeadm操作只需要在k8s-01上即可
国内源
- packages.cloud.google.com这里懂的都懂,下面改成阿里云源
cat <<EOF > /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=http://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=0
repo_gpgcheck=0
gpgkey=http://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg
http://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
k8s-01节点安装kubeadm和master相关依赖组建
yum install -y kubelet-1.24.0 kubeadm-1.24.0 kubectl-1.24.0 --disableexcludes=kubernetes
#将k8s-01节点的kubelet设置成开机启动:
systemctl enable --now kubelet
配置kubeadm文件
这里我们在k8s-01上配置打印init默认配置信息
kubeadm config print init-defaults >kubeadm-init.yaml
虽然kubeadm作为etcd节点的管理工具,但请注意kubeadm不打算支持此类节点的证书轮换或升级。长期计划是使用etcdadm来工具来进行管理。
因为我这里要做集群,请根据我这里的配置按需修改
[root@k8s-01 ~]# cat kubeadm-init.yaml
apiVersion: kubeadm.k8s.io/v1beta3
bootstrapTokens:
- groups:
- system:bootstrappers:kubeadm:default-node-token
token: abcdef.0123456789abcdef
ttl: 24h0m0s
usages:
- signing
- authentication
kind: InitConfiguration
localAPIEndpoint:
advertiseAddress: 192.168.31.10 #k8s-01 ip地址
bindPort: 6443
nodeRegistration:
criSocket: unix:///var/run/containerd/containerd.sock
imagePullPolicy: IfNotPresent
name: k8s-01
taints: null
---
apiServer:
timeoutForControlPlane: 4m0s
apiVersion: kubeadm.k8s.io/v1beta3
certificatesDir: /etc/kubernetes/pki
clusterName: kubernetes
controllerManager: {}
dns: {}
etcd:
local:
dataDir: /var/lib/etcd
imageRepository: registry.aliyuncs.com/google_containers #配置国内镜像源地址
kind: ClusterConfiguration
kubernetesVersion: 1.24.0
controlPlaneEndpoint: apiserver.frps.cn:8443 #高可用地址,我这里填写vip
networking:
dnsDomain: cluster.local
serviceSubnet: 10.96.0.0/12
podSubnet: 10.244.0.0/16
scheduler: {}
---
apiVersion: kubeproxy.config.k8s.io/v1alpha1
kind: KubeProxyConfiguration
mode: ipvs # kube-proxy 模式
---
apiVersion: kubelet.config.k8s.io/v1beta1
authentication:
anonymous:
enabled: false
webhook:
cacheTTL: 0s
enabled: true
x509:
clientCAFile: /etc/kubernetes/pki/ca.crt
authorization:
mode: Webhook
webhook:
cacheAuthorizedTTL: 0s
cacheUnauthorizedTTL: 0s
clusterDNS:
- 10.96.0.10
clusterDomain: cluster.local
cpuManagerReconcilePeriod: 0s
evictionPressureTransitionPeriod: 0s
fileCheckFrequency: 0s
healthzBindAddress: 127.0.0.1
healthzPort: 10248
httpCheckFrequency: 0s
imageMinimumGCAge: 0s
kind: KubeletConfiguration
cgroupDriver: systemd # 配置 cgroup driver
logging: {}
memorySwap: {}
nodeStatusReportFrequency: 0s
nodeStatusUpdateFrequency: 0s
rotateCertificates: true
runtimeRequestTimeout: 0s
shutdownGracePeriod: 0s
shutdownGracePeriodCriticalPods: 0s
staticPodPath: /etc/kubernetes/manifests
streamingConnectionIdleTimeout: 0s
syncFrequency: 0s
volumeStatsAggPeriod: 0s
检查配置文件是否有错误
[root@k8s-01 ~]# kubeadm init --config kubeadm-init.yaml --dry-run
正确如下
查看所需镜像列表
kubeadm config images list --config kubeadm-init.yaml
预先拉取镜像
#拉取镜像
kubeadm config images pull --config kubeadm-init.yaml
#检查镜像
ctr -n k8s.io i ls -q
#查看本地镜像
crictl images
#查看本地运行镜像
crictl ps -a
接下来开始初始化
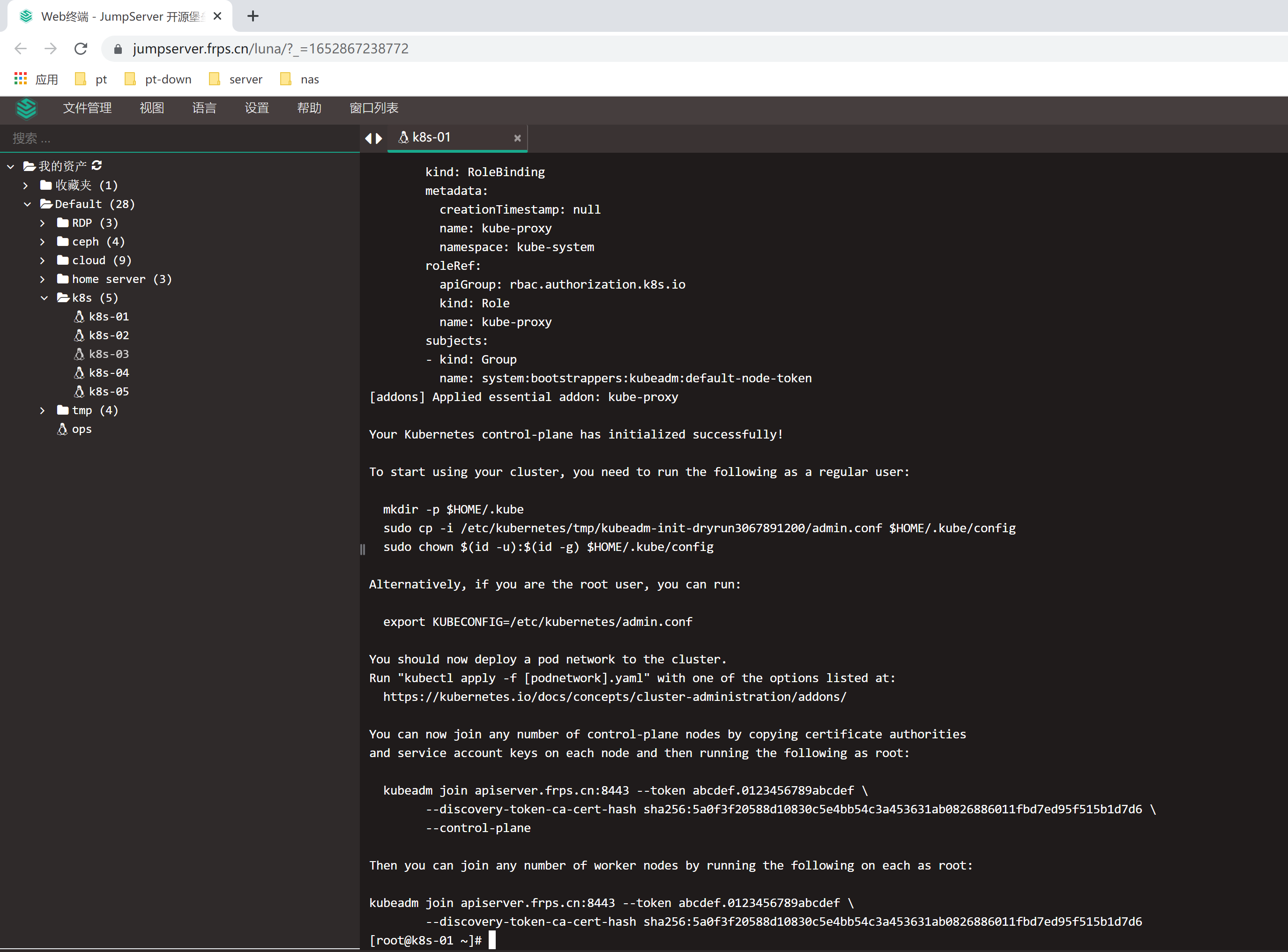
kubeadm init --config kubeadm-init.yaml --upload-certs
初始化完成
记住init后打印的token,复制kubectl的kubeconfig,kubectl的kubeconfig路径默认是~/.kube/config
mkdir -p $HOME/.kube
cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
chown $(id -u):$(id -g) $HOME/.kube/config
初始化的配置文件为保存在configmap里面
kubectl -n kube-system get cm kubeadm-config -o yaml
接下来执行kubectl就可以看到node了
[root@k8s-01 ~]# kubectl get node
NAME STATUS ROLES AGE VERSION
k8s-01 Ready control-plane 4m18s v1.24.0
Master节点配置(单节点跳过)
前面我们已经为所有master节点配置了一下服务
- nginx
- keeplived
- containerd
接下来只需要给其它master节点安装k8s组件
cat <<EOF > /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=http://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=0
repo_gpgcheck=0
gpgkey=http://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg
http://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
安装相关组件
yum install -y kubelet-1.24.0 kubeadm-1.24.0 kubectl-1.24.0 --disableexcludes=kubernetes
启动kubelet
systemctl enable --now kubelet
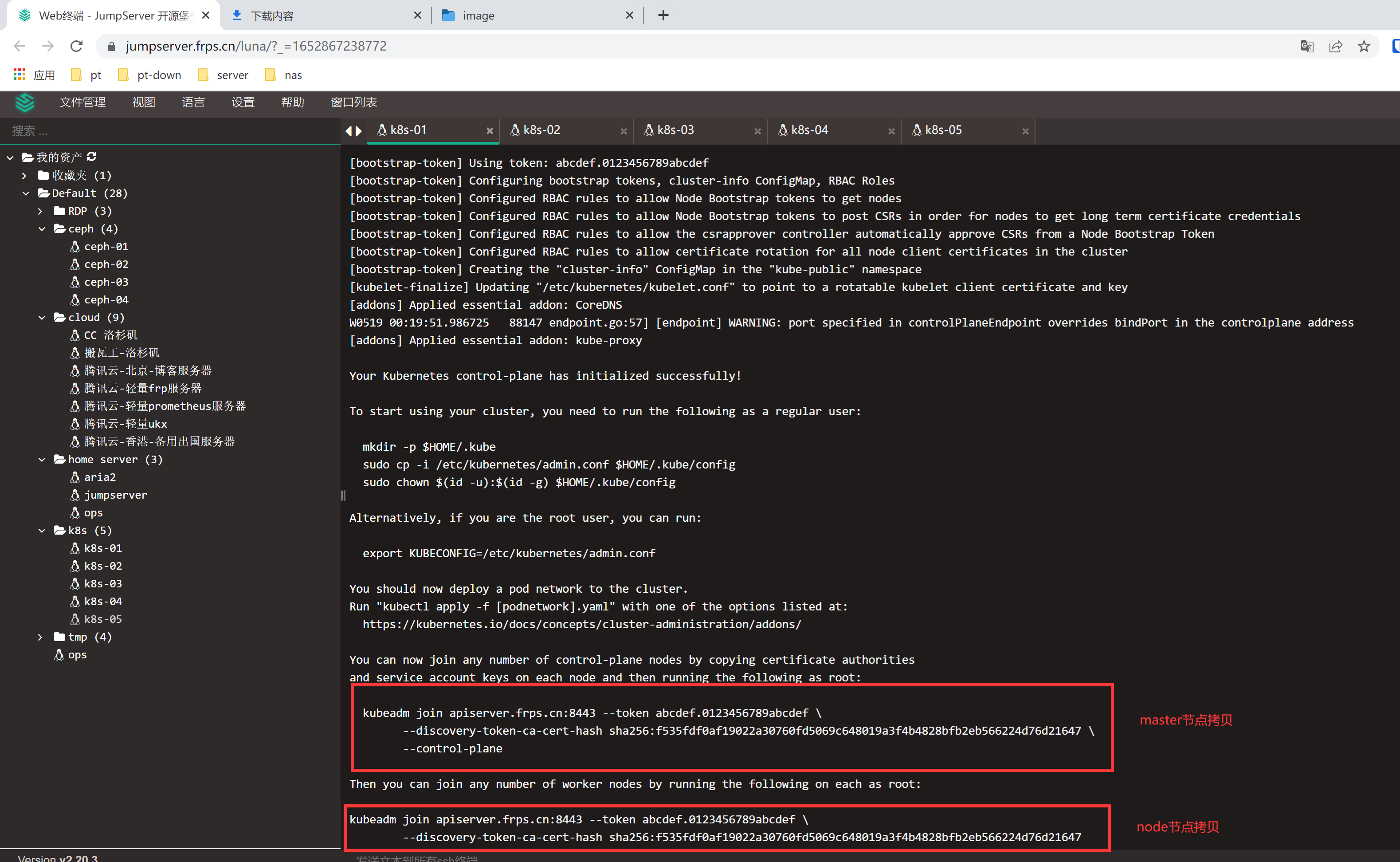
master执行添加节点
kubeadm join apiserver.frps.cn:8443 --token abcdef.0123456789abcdef
--discovery-token-ca-cert-hash sha256:a54c17e514edba57226f969268227b749d8bfb8802ae99112e08cbcabcd22ae0
--control-plane --certificate-key f7b0eb9c7e0aac2c95eef083c591950109434250a6df9cc0dc1ec9fb04461250
设置kubectl config文件
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
目前我们3台master节点已经添加完毕
[root@k8s-02 ~]# kubectl get node
NAME STATUS ROLES AGE VERSION
k8s-01 Ready control-plane 15m v1.24.0
k8s-02 Ready control-plane 6m25s v1.24.0
k8s-03 Ready control-plane 14m v1.24.0
Node节点配置
node节点安装kubeadm
cat <<EOF > /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=http://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=0
repo_gpgcheck=0
gpgkey=http://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg
http://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
安装相关组件
yum install -y kubeadm-1.24.0 --disableexcludes=kubernetes
添加join命令
kubeadm join apiserver.frps.cn:8443 --token abcdef.0123456789abcdef
--discovery-token-ca-cert-hash sha256:a54c17e514edba57226f969268227b749d8bfb8802ae99112e08cbcabcd22ae0
如果我们后续需要添加node节点时,可以到k8s-01节点执行下面的命令获取token相关信息
[root@k8s-01 ~]# kubeadm token create --print-join-command
kubeadm join apiserver.frps.cn:8443 --token sgvcen.qf87ykht9gopqe0d --discovery-token-ca-cert-hash sha256:f535fdf0af19022a30760fd5069c648019a3f4b4828bfb2eb566224d76d21647
如果我们添加某台节点异常了,修改后可以执行下面的命令,然后在重新join加入集群
kubeadm reset
验证所有服务器是否添加到集群中
[root@k8s-01 ~]# kubectl get node -o wide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
k8s-01 Ready control-plane 22m v1.24.0 192.168.31.10 <none> CentOS Linux 7 (Core) 5.17.8-1.el7.elrepo.x86_64 containerd://1.6.4
k8s-02 Ready control-plane 13m v1.24.0 192.168.31.11 <none> CentOS Linux 7 (Core) 5.17.8-1.el7.elrepo.x86_64 containerd://1.6.4
k8s-03 Ready control-plane 21m v1.24.0 192.168.31.12 <none> CentOS Linux 7 (Core) 5.17.8-1.el7.elrepo.x86_64 containerd://1.6.4
k8s-04 Ready <none> 107s v1.24.0 192.168.31.13 <none> CentOS Linux 7 (Core) 5.17.8-1.el7.elrepo.x86_64 containerd://1.6.4
k8s-05 Ready <none> 6m6s v1.24.0 192.168.31.14 <none> CentOS Linux 7 (Core) 3.10.0-1160.62.1.el7.x86_64 containerd://1.6.4
网络配置
这个时候其实集群还不能正常使用,因为还没有安装网络插件,接下来安装网络插件,可以在文档 https://kubernetes.io/docs/setup/production-environment/tools/kubeadm/create-cluster-kubeadm/ 中选择我们自己的网络插件。
安装 flannel
wget http://down.i4t.com/k8s1.24/kube-flannel.yml
根据需求修改网卡配置,我这里以eth0为主
containers:
- name: kube-flannel
image: quay.io/coreos/flannel:v0.12.0-amd64
command:
- /opt/bin/flanneld
args:
- --ip-masq
- --kube-subnet-mgr
- --iface=eth0 # 如果是多网卡的话,指定内网网卡的名称
温馨提示: 在kubeadm.yaml文件中设置了podSubnet网段,同时在flannel中网段也要设置相同的。 (我这里默认就是相同的配置)
执行
[root@k8s-01 ~]# kubectl apply -f kube-flannel.yml
接下来我们所有的pod都可以正常运行了
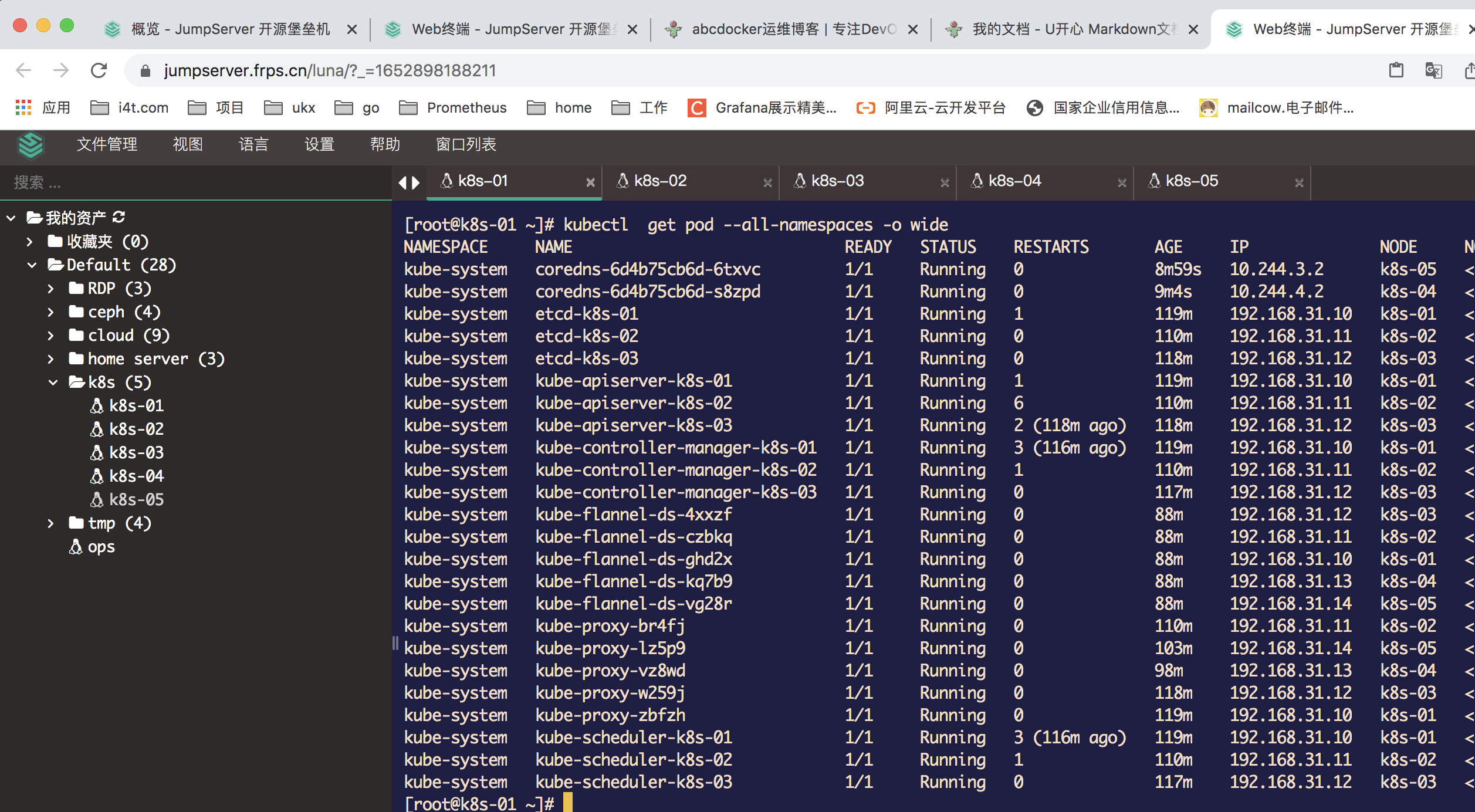
安装配置calico网络插件(与flannel只选其一)
下载部署文件:
curl https://docs.projectcalico.org/manifests/calico.yaml -O
执行:
kubectl apply -f calico.yaml
验证结果
kubectl get pod -A -owide
验证集群
等kube-system命名空间下的Pod都为Running,这里先测试一下dns是否正常
cat<<EOF | kubectl apply -f -
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx
spec:
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- image: nginx:alpine
name: nginx
ports:
- containerPort: 80
---
apiVersion: v1
kind: Service
metadata:
name: nginx
spec:
selector:
app: nginx
type: NodePort
ports:
- protocol: TCP
port: 80
targetPort: 80
nodePort: 30001
---
apiVersion: v1
kind: Pod
metadata:
name: busybox
namespace: default
spec:
containers:
- name: busybox
image: abcdocker9/centos:v1
command:
- sleep
- "3600"
imagePullPolicy: IfNotPresent
restartPolicy: Always
EOF
创建Pod后我们进行检查
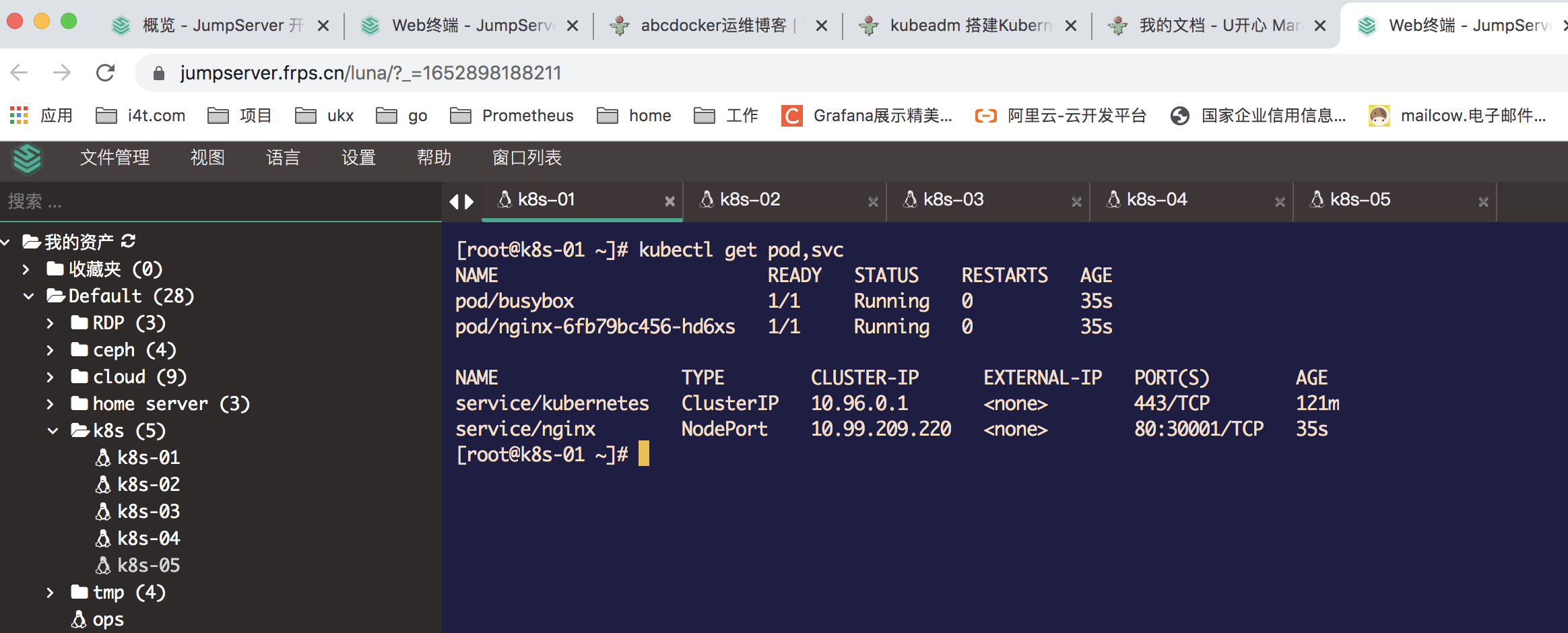
使用nslookup查看是否能返回地址
[root@k8s-01 ~]# kubectl exec -ti busybox -- nslookup kubernetes
Server: 10.96.0.10
Address: 10.96.0.10#53
Name: kubernetes.default.svc.cluster.local
Address: 10.96.0.1
测试nginx svc以及Pod内部网络通信是否正常
for i in k8s-01 k8s-02 k8s-03 k8s-04 k8s-05
do
ssh root@$i curl -s 10.99.209.220 #nginx svc ip
ssh root@$i curl -s 10.244.3.4 #pod ip
done
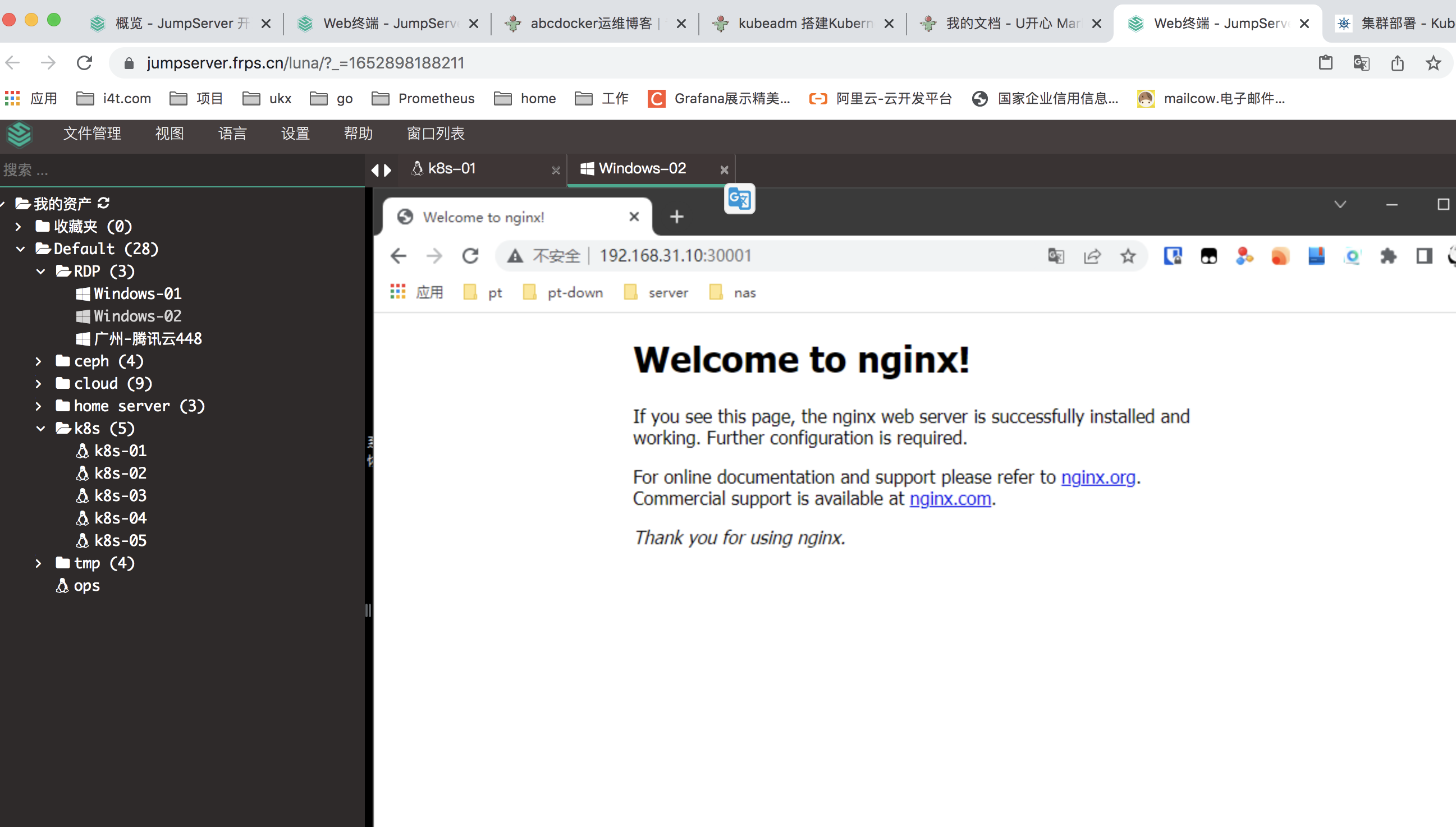
访问宿主机nodePort端口
Kubernetes kubectl 命令自动补全
评论区