



环境centos 7.9
kubernetes 1.23.1
docker 20.10.8
[control-plane] Creating static Pod manifest for "kube-scheduler"
[etcd] Creating static Pod manifest for local etcd in "/etc/kubernetes/manifests"
[wait-control-plane] Waiting for the kubelet to boot up the control plane as static Pods from directory "/etc/kubernetes/manifests". This can take up to 4m0s
[kubelet-check] Initial timeout of 40s passed.
[kubelet-check] It seems like the kubelet isn't running or healthy.
[kubelet-check] The HTTP call equal to 'curl -sSL http://localhost:10248/healthz' failed with error: Get http://localhost:10248/healthz: dial tcp [::1]:10248: connect: connection refused.
[kubelet-check] It seems like the kubelet isn't running or healthy.
[kubelet-check] The HTTP call equal to 'curl -sSL http://localhost:10248/healthz' failed with error: Get http://localhost:10248/healthz: dial tcp [::1]:10248: connect: connection refused.
[kubelet-check] It seems like the kubelet isn't running or healthy.
[kubelet-check] The HTTP call equal to 'curl -sSL http://localhost:10248/healthz' failed with error: Get http://localhost:10248/healthz: dial tcp [::1]:10248: connect: connection refused.
[kubelet-check] It seems like the kubelet isn't running or healthy.
[kubelet-check] The HTTP call equal to 'curl -sSL http://localhost:10248/healthz' failed with error: Get http://localhost:10248/healthz: dial tcp [::1]:10248: connect: connection refused.
[kubelet-check] It seems like the kubelet isn't running or healthy.
[kubelet-check] The HTTP call equal to 'curl -sSL http://localhost:10248/healthz' failed with error: Get http://localhost:10248/healthz: dial tcp [::1]:10248: connect: connection refused.
Unfortunately, an error has occurred:
timed out waiting for the condition
This error is likely caused by:
- The kubelet is not running
- The kubelet is unhealthy due to a misconfiguration of the node in some way (required cgroups disabled)
If you are on a systemd-powered system, you can try to troubleshoot the error with the following commands:
- 'systemctl status kubelet'
- 'journalctl -xeu kubelet'
Additionally, a control plane component may have crashed or exited when started by the container runtime.
To troubleshoot, list all containers using your preferred container runtimes CLI, e.g. docker.
Here is one example how you may list all Kubernetes containers running in docker:
- 'docker ps -a | grep kube | grep -v pause'
Once you have found the failing container, you can inspect its logs with:
- 'docker logs CONTAINERID'
error execution phase wait-control-plane: couldn't initialize a Kubernetes cluster
: running command: sudo /usr/bin/kubeadm init --config /var/lib/kubeadm.yaml --ignore-preflight-errors=DirAvailable--etc-kubernetes-manifests,DirAvailable--data-minikube,FileAvailable--etc-kubernetes-manifests-kube-scheduler.yaml,FileAvailable--etc-kubernetes-manifests-kube-apiserver.yaml,FileAvailable--etc-kubernetes-manifests-kube-controller-manager.yaml,FileAvailable--etc-kubernetes-manifests-etcd.yaml,Port-10250,Swap
.: exit status 1
* Sorry that minikube crashed. If this was unexpected, we would love to hear from you:
- https://github.com/kubernetes/minikube/issues/new
看上面的问题像是kubelet启动失败了,执行命令tail /var/log/messages查看进一步的原因:
Jun 8 09:45:35 minikube kubelet: F0608 09:45:35.392302 24268 server.go:266] failed to run Kubelet: failed to create kubelet: misconfiguration: kubelet cgroup driver: "cgroupfs" is different from docker cgroup driver: "systemd"
Jun 8 09:45:35 minikube systemd: kubelet.service: main process exited, code=exited, status=255/n/a
Jun 8 09:45:35 minikube systemd: Unit kubelet.service entered failed state.
Jun 8 09:45:35 minikube systemd: kubelet.service failed.
上述日志表明:kubelet的cgroup driver是cgroupfs,docker的 cgroup driver是systemd,两者不一致导致kubelet启动失败。
解决方法:
1, 尝试过修改kubelet的cgroup dirver(文件位置:/etc/systemd/system/kubelet.service.d/10-kubeadm.conf),但是每次启动minikube时会被覆盖掉,于是只能放弃这种处理方式,转去修改docker的cgroup dirver设置;
2, 打开文件/usr/lib/systemd/system/docker.service,如下图,将红框中的--exec-opt native.cgroupdriver=systemd 添加到execStart 里面:
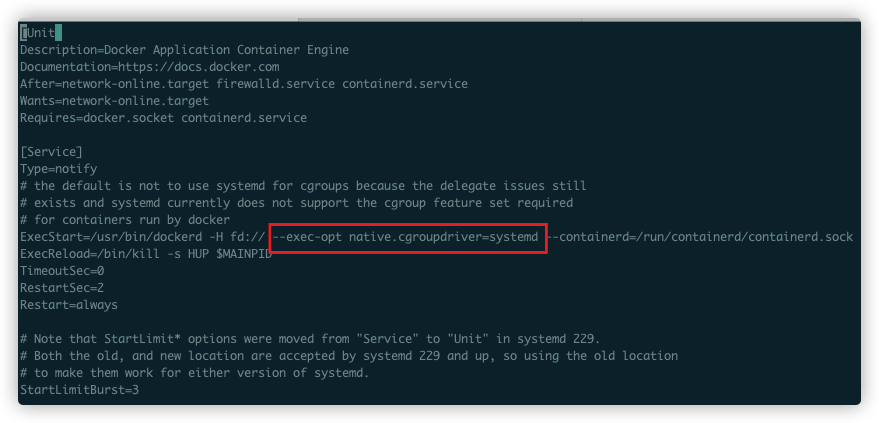
3, 重新加载配置信息,重启docker服务:
systemctl daemon-reload && systemctl restart docker
重新初始化集群。成功。
评论区